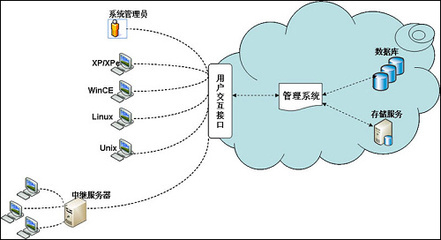
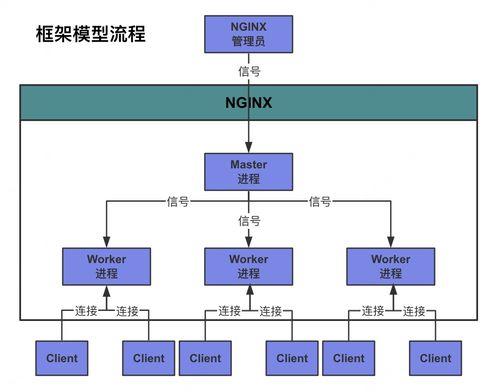
Netflix如何在上万台机器中管理微服务 史上最全信息管理服务解析
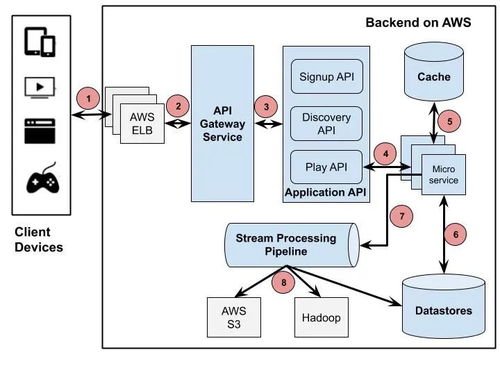
Netflix作为全球领先的流媒体服务提供商,其技术架构以微服务为核心,支撑着全球数亿用户的观影需求。面对上万台分布式机器的复杂环境,Netflix构建了一套高度自动化、可扩展且极具韧性的微服务管理体系。本文将深入剖析其核心信息管理服务,揭示其背后高效运转的秘密。
一、核心基石:Netflix自研的微服务平台
Netflix的微服务管理并非依赖于单一工具,而是一个由多个自研核心组件构成的生态系统,其中最为关键的是Netflix OSS(Open Source Software)套件。这些组件协同工作,确保服务在上万台机器间无缝运行。
- Eureka:服务注册与发现
- 角色:微服务架构的“电话簿”。每个微服务实例启动时,都会向Eureka服务器注册自己的网络位置(如IP和端口)。服务消费者通过查询Eureka来动态发现所需服务的可用实例,而无需硬编码服务地址。
- 在上万台机器中的管理:Eureka采用对等复制架构,多个Eureka服务器相互注册,形成集群。即使部分服务器宕机,注册表信息依然能在集群中保持同步,确保了高可用性。服务实例通过发送心跳来维持其“健康”状态,失效实例会被自动剔除。
- Ribbon:客户端负载均衡
- 角色:基于客户端的智能负载均衡器。当服务消费者通过Eureka获取到某个服务的多个实例列表后,Ribbon会介入,根据配置的策略(如轮询、随机、响应时间加权等)选择一个实例发起请求。
- 在上万台机器中的管理:将负载均衡逻辑从中心化的负载均衡器(如Nginx)转移到每个客户端,消除了单点故障和性能瓶颈,使得流量分发更加分散和高效,完美适配大规模机器集群。
- Hystrix:熔断与容错
- 角色:分布式系统的“断路器”。当某个微服务调用失败(如超时、异常)达到一定阈值时,Hystrix会快速失败(熔断),阻止连锁故障在整个系统中蔓延,并可提供降级逻辑(如返回缓存数据或默认值)。
- 在上万台机器中的管理:在庞大的服务网格中,局部故障是常态。Hystrix为每个依赖服务(如上万次调用中的某个数据库服务)维护独立的线程池或信号量隔离,确保一个服务的延迟或失败不会拖垮整个应用。它通过实时的指标流(Metrics Stream)帮助运维人员全局监控系统健康状况。
- Zuul:动态路由与网关
- 角色:系统的“前门”和“智能路由器”。所有外部请求首先到达Zuul网关,它可以进行身份验证、监控、动态路由、压力测试、安全防护等。
- 在上万台机器中的管理:Zuul作为边缘服务,能够将流量动态路由到后台上万台机器中的具体服务实例。它与Eureka集成,自动感知服务实例的变化,实现无缝的扩容和故障转移。
二、协调与配置:确保全局一致性与敏捷性
管理上万台机器,意味着需要高效地协调服务部署和统一管理配置。
- Spinnaker:持续交付平台
- 角色:Netflix开源的多云持续交付平台,负责微服务的构建、测试、部署和发布全流程。
- 在上万台机器中的管理:Spinnaker支持复杂的部署策略,如蓝绿部署、金丝雀发布和滚动更新。它可以直接与云供应商(如AWS)的API交互,在上万台虚拟机或容器中自动化执行这些策略,确保新服务版本能够安全、可控地滚动到整个集群,并能在出现问题时快速回滚。
- Archaius:动态配置管理
- 角色:Netflix的配置管理客户端库,支持动态、类型化的属性。
- 在上万台机器中的管理:微服务的配置(如数据库连接、功能开关)需要能够在不重启服务的情况下动态更改。Archaius与配置源(如数据库、文件系统)集成,并提供了高效的轮询机制,使得运行在上万台机器上的所有服务实例能近乎实时地获取最新的配置变更,实现全局配置的统一管理和快速生效。
三、可观察性与监控:洞察每一台机器的脉搏
没有监控,管理就无从谈起。Netflix建立了全面的可观察性体系。
- Atlas:近实时运营监控平台
- 角色:Netflix自研的时序数据库和监控系统,用于存储、索引和查询海量的时间序列指标数据。
- 在上万台机器中的管理:每个微服务、每个容器、每台主机都会每秒向Atlas发送数十甚至上百个指标(如CPU、内存、请求量、延迟、错误率)。Atlas能够高效处理这每秒数十亿的数据点,并提供强大的查询语言,让工程师能够快速定位从全局业务指标到单台机器性能的任何问题。
- Vector:实例性能监控代理
- 角色:部署在每台EC2实例上的轻量级代理,负责收集主机级别的系统指标(如CPU、内存、磁盘、网络)。
- 在上万台机器中的管理:Vector作为统一的数据采集器,确保了所有机器监控数据格式和上报方式的一致性,简化了大规模基础设施的监控数据收集工作流。
四、通信与韧性:服务间高效可靠的对话
在庞大的服务网络中,通信的效率与可靠性至关重要。
- gRPC与RESTful API:Netflix内部广泛使用基于HTTP/2的gRPC框架进行高性能、低延迟的服务间通信,同时也大量使用RESTful API。统一的标准简化了服务间的集成。
- 自适应并发限制与优先级排队:Netflix开发了如自适应并发限制等机制,系统能够根据下游服务的健康状态和自身容量,动态调整发出的请求数量,防止过载,这在上万台机器同时发起请求的场景下尤为重要。
五、数据管理与缓存:应对海量请求
- EVCache:分布式内存缓存
- 角色:Netflix基于Memcached构建的分布式缓存服务,主要用于会话存储和个性化推荐等热数据缓存。
- 在上万台机器中的管理:EVCache客户端与部署在多个AWS可用区的Memcached集群交互,通过一致性哈希将数据分布到上千个缓存节点上。它提供了跨区域复制功能,确保即使整个可用区宕机,数据依然可用,极大提升了读性能和数据韧性。
文化、自动化与持续演进
Netflix能在上万台机器中成功管理微服务,除了上述强大的技术工具栈,更深层的原因在于其工程师文化:
- 自由度与责任:赋予团队对服务的完全所有权(构建、运行、维护)。
- 混沌工程:通过如Chaos Monkey(随机终止生产环境实例)等工具主动注入故障,验证系统的韧性,确保服务能经受住真实世界中任何单台甚至多台机器失效的考验。
- 全自动化:从部署、监控到故障响应,尽可能减少人工干预。
这套以Netflix OSS为核心,结合强大的内部平台、全面的监控和先进的工程实践所构成的“信息管理服务体系”,使得Netflix的微服务架构不仅能够支撑惊人的规模,更具备了应对变化与故障的卓越韧性,堪称分布式系统管理的典范。
如若转载,请注明出处:http://www.gzjiudaomingpin.com/product/82.html
更新时间:2026-06-19 11:40:42